Introduction to RAG
RAG(Retrieval-Augmented Generation),意思是将外部的知识引入到大模型生成过程中,使得模型能生成更加准确和详实的回复。
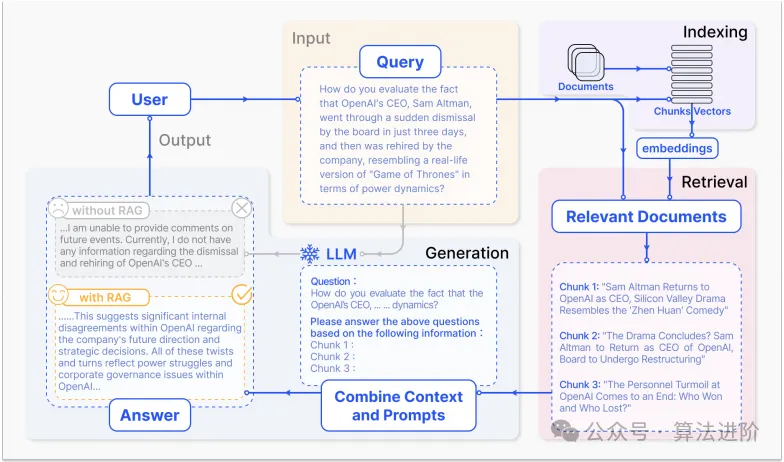
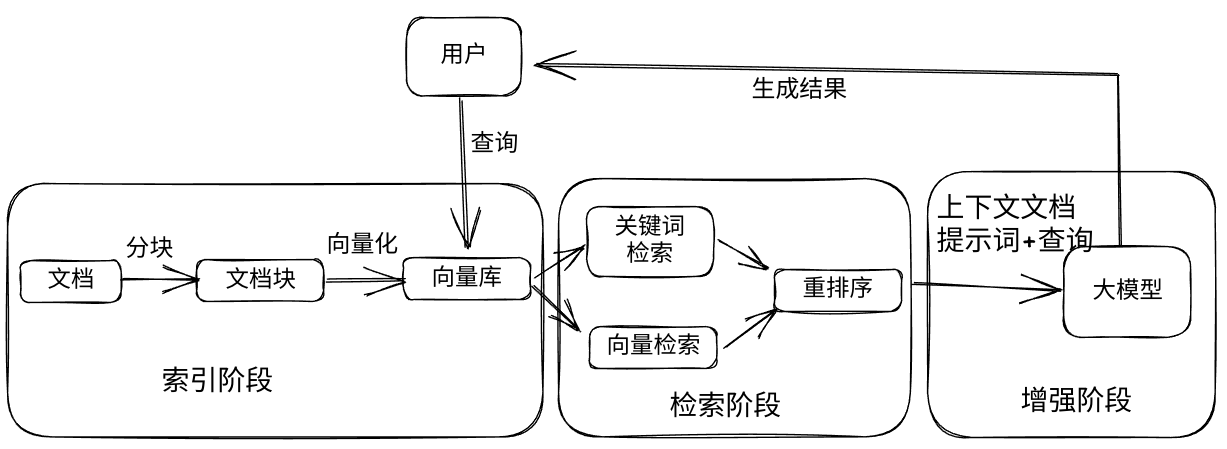
RAG是一种大模型的应用架构模式,遵循这种模式的系统通常包含知识库,并按照如下的流程进行工作:
- 索引外部的知识,将知识索引后在模型生成的时候进行检索和使用。这里的知识库是个通用的概念,只有是外部的知识,存储后可以被检索和应用都算遵循这种模式。现在业界常用的是向量数据库,通过将外部知识分块并向量化存储入向量数据库。当然其他类型的知识数据库也都有合适的适用场景,例如图数据库等。
- 检索外部的知识,从外部的知识库中将向关联的知识检索出来,向量库可以通过语义相似度进行检索,所以比较常用。也可以结合其他类型的数据库形式进行检索。
- 增强上下文知识,将检索后的数据作为上下文的一部分或者提示词的一部分,结合问题,形成模板提供给大语言模型。
- 生产结果数据,并标注外部知识的信息来源等,以方便用户进行可信度的识别。
RAG这种将外部知识引入大模型应用的机制,类似开卷考试,大模型可以根据相关的外部知识学习,进行结果的生成,应用到了大模型本身的通识知识,推理学习能力,并查资料补齐专业知识后进行回答。
大模型容易出现幻觉、缺乏专业知识、回答缺乏可解释性问题,而RAG技术通过外挂专业的知识库、在生成答案时结合知识库回答问题、同时在最终生成结果中展示知识库信息来源,一定程度上有效的解决了这3大问题。
RAG的价值和应用场景
RAG可以减少模型在不了解的领域产生幻觉,利用通用知识胡说八道。并可以提高模型的知识边界和范围,避免每次都进行训练,增加模型的适应和泛化能力。
RAG主要可以构建:
- 知识问答,通过构建企业知识库,提供问答应用系统。
- 业务支撑,RAG作为一个组件,构建其他业务系统。
- 智能客服,集成到企业客服中,快速准确的回答企业业务问题,提高服务效率和客户满意度。
RAG的评估方法
评估指标:
- 检索质量:召回率和精确度
- 生成质量:答案忠诚度,答案精确度
- 系统性能:端到端耗时,资源消耗
RAG的优化方法
- 检索优化:混合检索,调整Top-K
- 模型优化:模型增训微调
- 提示词优化:提示词工程
RAG参考架构
 ![[Pasted_image_20250426230922.png]]
![[Pasted_image_20250426230922.png]]
![[building-RAG-from-scratch 2025-04-26 22.30.57.excalidraw]]
 ![[Pasted_image_20250501165323.png]]
![[Pasted_image_20250501165323.png]]
RAG参考架构实现
参见:《学习LLamaIndex第一个程序》帖子