使用AI辅助数据治理
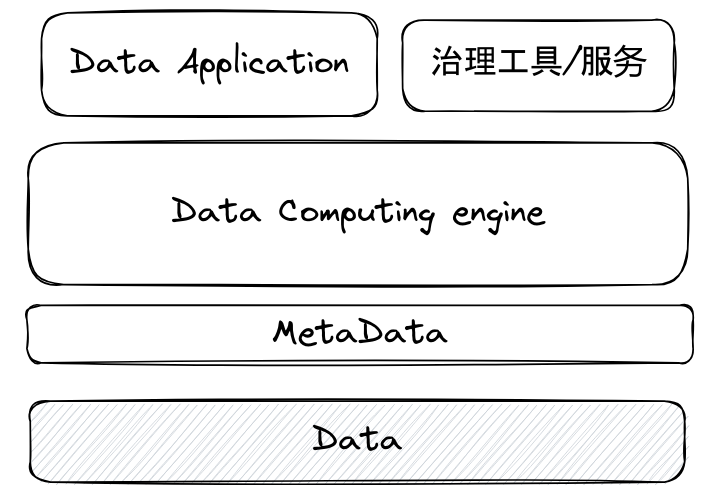
传统的数据治理工具,构建在计算引擎和元数据服务之上,进行数据建模、数据抽取、加工、开放等操作,为应用提供数据。
AI大语言模型引入后,需要引入一个中间层,将治理工具/服务的知识进行沉淀,才能将数据的知识充分抽象,从而提供给模型进行辅助治理工作。
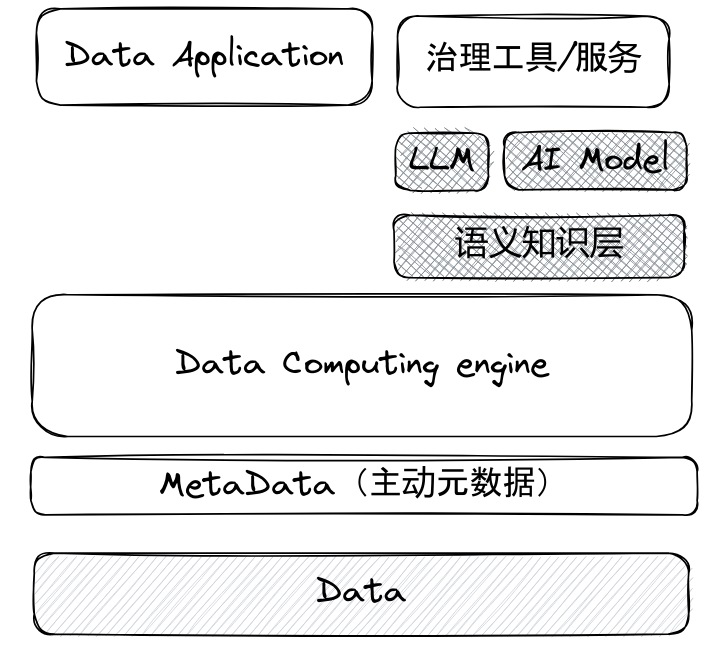
增加的层主要负责如下工作:
- 主动元数据的分析和生成;
- 语言知识层的知识抽象和沉淀(借助LLM和传统AI模型或者统计学算法);
- 通过元数据以及语义知识层的知识,协同提供给LLM进行辅助数据治理工作。
AI辅助数据应用(治理/服务)工作方向是:
- 数据特征的识别及推荐;
- 数据标签的识别及推荐;
- 数据关系的识别及推荐;
- 数据标准的识别及推荐;
- 数据质量的识别及标记;
- 各类数据映射的自动生成;
- 各类数据加工逻辑代码/SQL的生成;
- 智能问数;
- … …。
这些AI功能理论上能较大提升治理的效率。具体能提升多少,需要看业务复杂程度以及模型的能力,需要在实际场景中进行测量。
想起一个事情,之前某产品,规划的一个需求是基于AI辅助提效的能力。原始主要想解决的是通过特征识别、关系识别,结合人工确认进行自动化辅助建模,从而提升建模的效率,和上述思路比较接近。而该需求最终被研发实现成了按照数据源表结构自动生成ETL语句,虽然最终活是交差了,但离原始目标差别还挺大的,并没有积累相关能力。
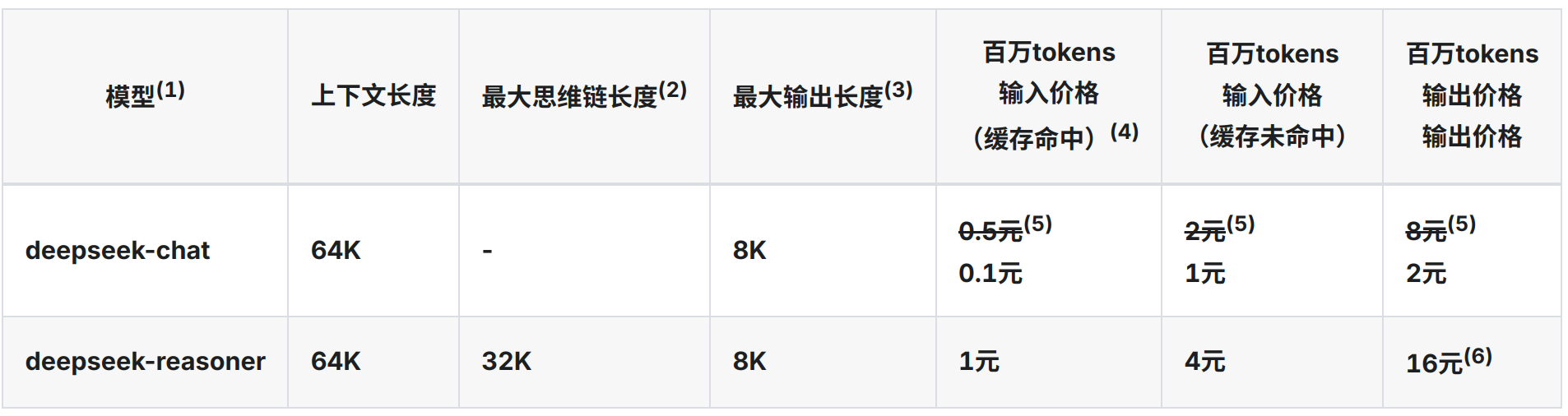
现在大模型门槛很低了,如下图Deepseek API的价格。我们可以通过开源的工具和开放的AI服务来进行上述思路的验证。