1、准备
1.1、查看驱动
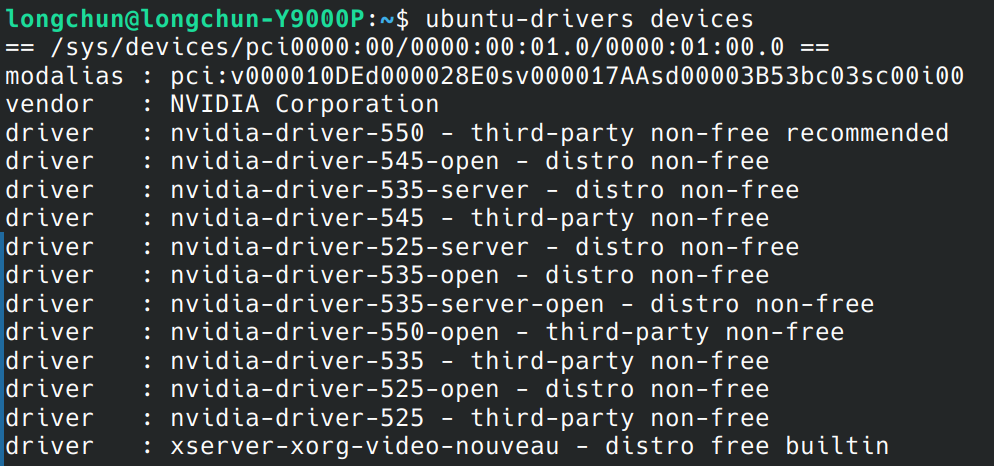 推荐550版本,如下图,切换驱动版本(当前是525,对CUDA版本支持有点低),同时查了下,官网的最新包是550.67,但是安装的时候提示一个错误,还是使用550.54。
推荐550版本,如下图,切换驱动版本(当前是525,对CUDA版本支持有点低),同时查了下,官网的最新包是550.67,但是安装的时候提示一个错误,还是使用550.54。
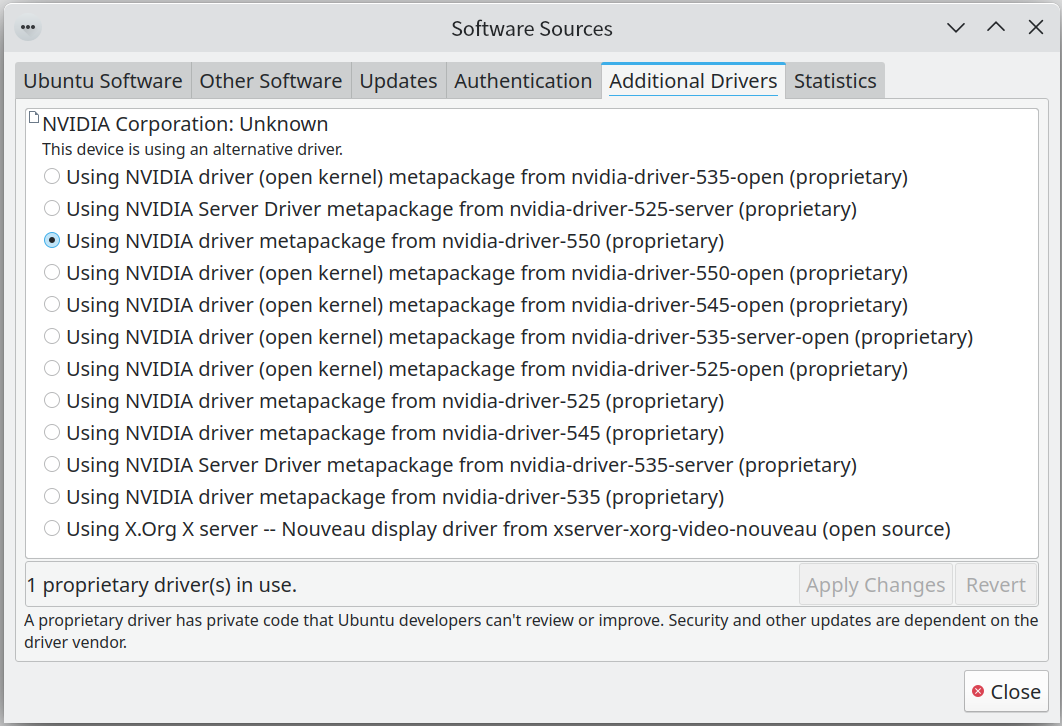 查看下当前内核支持的驱动,如下图:
查看下当前内核支持的驱动,如下图:
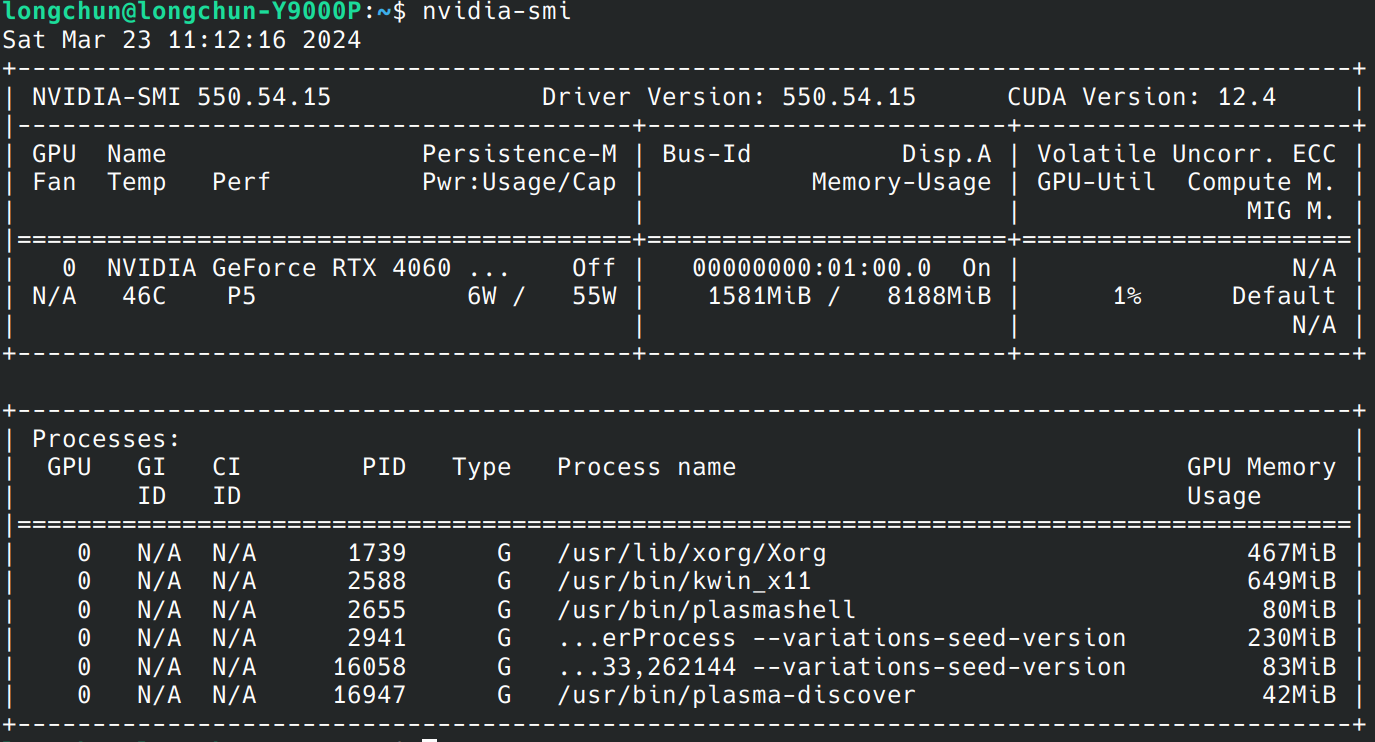 可以看到,CUDA版本已经支持到最新的12.4了。
可以看到,CUDA版本已经支持到最新的12.4了。
查看了下开源的nouvean已经没被加载了,所以不需要禁用。
lsmod | grep nou
#无输出
然后到Pytorch官网看下,最新版本是2.2.1,CUDA可以支持到12.1。

1.2、下载
CUDA官网,看了下,12.1版本已经有更新1了,下载的CUDA Tools 12.1.1版本。
wget https://developer.download.nvidia.com/compute/cuda/12.1.1/local_installers/cuda_12.1.1_530.30.02_linux.run
再去下载个加速库cuDNN,也是去官网找下,最新的9.0.0。上个版本是8.9.7,本着稳定的考虑,下个8.9.7 for CUDA 12.x的版本。
2、安装CUDA和cuDNN
2.1、安装CUDA Tools
sudo sh ./cuda_12.1.1_530.30.02_linux.run
装的时候不需要选驱动,CUDA包中的驱动比较老。然后继续,安装完毕。
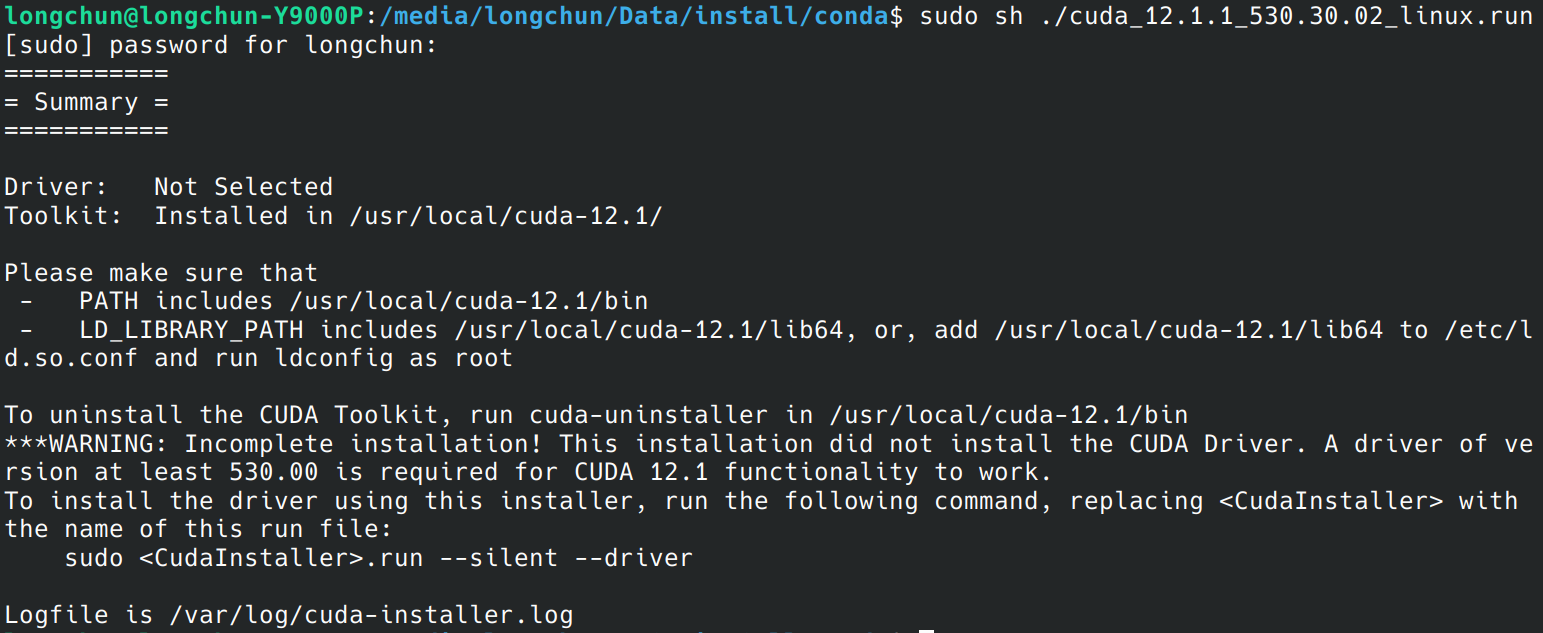
设置环境变量:
vi ~/.profile
#添加
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64
export PATH=$PATH:/usr/local/cuda/bin
export CUDA_HOME=$CUDA_HOME:/usr/local/cuda
. .profile
查看安装结果:

2.2、安装cuDNN
sudo cp /var/cudnn-local-repo-ubuntu2204-8.9.7.29/cudnn-local-08A7D361-keyring.gpg /usr/share/keyrings/
sudo dpkg -i cudnn-local-repo-ubuntu2204-8.9.7.29_1.0-1_amd64_12.x.deb
(Reading database ... 349826 files and directories currently installed.)
Preparing to unpack cudnn-local-repo-ubuntu2204-8.9.7.29_1.0-1_amd64_12.x.deb ...
Unpacking cudnn-local-repo-ubuntu2204-8.9.7.29 (1.0-1) over (1.0-1) ...
Setting up cudnn-local-repo-ubuntu2204-8.9.7.29 (1.0-1) ...
测试cuDNN安装结果
sudo apt install libcudnn8-samples
cp -r /usr/src/cudnn_samples_v8/ ~
cd ~/cudnn_samples_v8/mnistCUDNN/
sudo apt install libfreeimage3 libfreeimage-dev
make clean && make
./mnistCUDNN
xxx
xxx
Test passed!
3、安装Pytorch
准备conda创建环境并安装
conda activate llm_test
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia
import torch
print(torch.cuda.is_available());
True
4、测试Pytorch
4.1、下载模型
以GPT-2为例,从huggingface下载: https://huggingface.co/uer/gpt2-chinese-poem/tree/main
如果网络不通,也可以从hf-mirror.com下载,使用一个python的下载工具:
git clone https://github.com/LetheSec/HuggingFace-Download-Accelerator.git
cd HuggingFace-Download-Accelerator
python hf_download.py --model uer/gpt2-chinese-poem --save_dir ./hf_hub
下载后放在缓存中:
用一个小程序进行验证:
from transformers import BertTokenizer, GPT2LMHeadModel,TextGenerationPipeline
tokenizer = BertTokenizer.from_pretrained("/home/xxxxxx/.cache/huggingface/hub/models--uer--gpt2-chinese-poem")
model = GPT2LMHeadModel.from_pretrained("/home/xxxxxx/.cache/huggingface/hub/models--uer--gpt2-chinese-poem")
text_generator = TextGenerationPipeline(model, tokenizer)
result = text_generator("[CLS] 无 尽 长 江 滚 滚 来 ,", max_length=50, do_sample=True)
print(result)
生成的结果:
