安装whisper.cpp去转换语音到文字
1. 条件
Debian 12
GPU 4060
2. 安装
安装编译工具build_essential
sudo apt install build-essential
克隆whisper.cpp仓库,并编译
git clone https://github.com/ggerganov/whisper.cpp.git
cd whisper.cpp
make -j
3. 使用
下载模型
cd model
./download-ggml-model.sh large-v3-turbo
./download-ggml-model.sh large-v3
ll -rt
1624555275 May 15 01:00 ggml-large-v3-turbo.bin
3095033483 May 17 19:40 ggml-large-v3.bin
格式是m4a,发现不直接支持,安装ffmpeg进行转换:
ffmpeg -i ./models/sounds/20250509_095502.m4a -acodec pcm_s16le -ac 1 -ar 16000 ./models/sounds/20250509_095502.wav
ffmpeg -i ./models/sounds/20250513_175944.m4a ./models/sounds/20250513_175944.wav
直接进行转换,行是行,但是有点慢,提示CPU在工作
$ ./build/bin/whisper-cli --device cuda --language Chinese -nt -otxt -m /home/xxxxx/workdir/git/work/whisper.cpp/models/ggml-large-v3-turbo.bin -f ./models/sounds/20250513_175944.wav
./build/bin/whisper-cli -m ../../../llm/whisper.cpp/models/belle-whisper-large-v3-turbo-zh.bin -f ./models/sounds/20250513_175944.wav -l Chinese
编译成GPU版本,然后试试,确实快了很多。
cmake -B build -DGGML_CUDA=1
cmake --build build -j --config Release
make GGML_CUDA=1 -j10
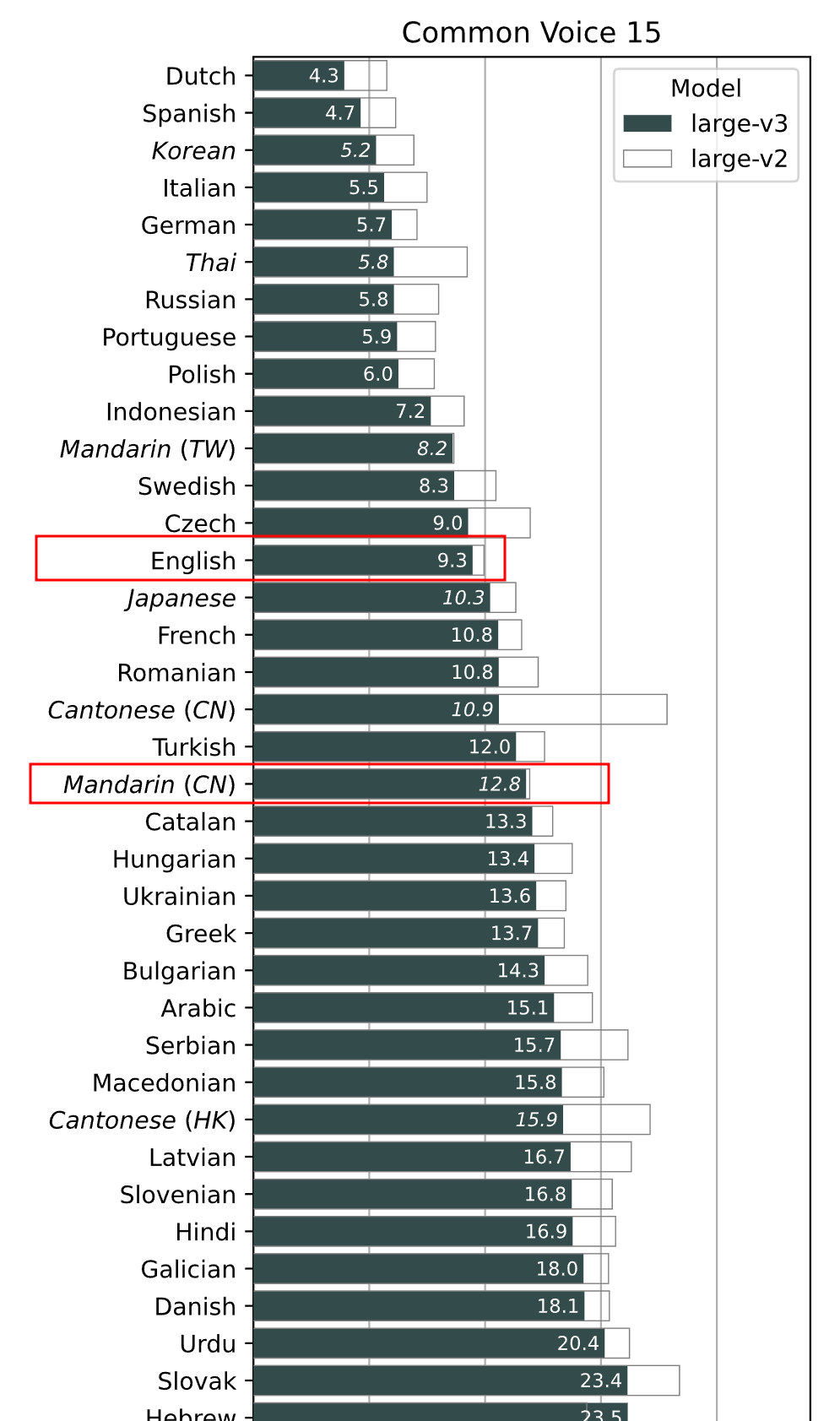
但是模型的效果真的很不好,估计是转换成ggml的模型都是英文原版的模型,针对西语效果好但是中文支持差。查看了下whisper的官网,发现确实如此。
找了下有中文的增训版本BELLE: Be Everyone's Large Language model Engine
https://github.com/LianjiaTech/BELLE
https://github.com/yeyupiaoling/Whisper-Finetune
发布到HuggingFace上了,后面使用HuggingFace的模型尝试下。或者将HuggingFace的模型转换为Whisper.cpp的格式进行测试下。
Whisper官网公布的准确度:
 ![[Pasted_image_20250519000926.png]]
![[Pasted_image_20250519000926.png]]