为什么要自然语言2SQL?
数据分析
数据用途除了支撑业务系统自身业务流程,还可以作分析。分析数据一直是企业决策的重要依据。分析数据经历过这些阶段:
- 固定报表:那个时候是数据工程师根据业务需要,整理数据,开发出可视化报表,并生成调度任务,定期给相关业务部门或者领导提供生成好的报表结果,一般领导有需求,到分析和生成报表,周/月为单位。
- 自助分析:那些数据分析师或者数据科学家,采用可视化拖拽式的工具,按照自己的思路展开,进行数据的分析,这个时候可以分钟/小时级别进行数据的探索,领导们提出大的思路,数据科学家找到原因。
- 智能洞察:这个阶段主要是给一线业务人员或者领导快速按照自己的分析需要进行数据查询和分析的。业务人员/领导一般不熟悉技术,但是他们才是数据的最终用户,对业务很敏感。让他们能直接的使用数据,才能减少数据到最终用户的路径。这个时候技术就应该提供一个很便捷的方式,自然语言是交流的最好选择。
刚才提到,数据的思维是不断完善的,一般有个想法,进行数据分析后,如果和想法一致,则会深入的探索分析,如果不一致,也需要尽快看其他分析角度。这种迭代一定要在最终使用人脑的海里不断的深化,才能形成数据思维,支撑到他们的决策,从而将数据的价值快速体现出来。
另外,看到这些数据后,还需要能给出分析,辅助人进行原因分析和深层地洞察,验证或推演,从而支撑自己的决策。
用户难点
用户如果通过自然语言交互,受到语言本身灵活性,自身经验和平时交流习惯的影响,会有这些复杂性:
- 包含的术语多,专业性强,有很多的“黑话”,这些行业特有的专业知识,很难理解,需要告诉大模型如何去分析他们的真实含义。
- 不同的人提问的方式灵活多样,甚至不同的人导致的上下文含义也不同。例如:领导说xxx情况,可能是想了解总体分布。而具体业务人员问的xxx情况,可能向了解情况的细节,甚至他负责的领域的细节。
- 有些语言的表达是模糊的,主观的,例如:某业务人员说清帮我分析下高风险的事件。到底什么是高风险,怎么定义高风险的阈值,这些都需要定义,甚至二次澄清。
- 用户问的一连串问题,后面的和前面的是有丰富联系的,例如刚问了某街道的某种分布情况。客户又问,那另一个街道呢?这里隐含是指和上几个问题一致的上下文。
- 用户问了问题,得到数据后,如果不知道这些数据是怎么计算的,也会有一些疑惑。数据的可解释性对问问题的业务人员也很重要,要让他们信任数据。这个也是他们能够反复使用和依赖这些工具的基础。
技术困难
持续演进
NL2SQL现状
通过大语言模型进行的NL2SQL发展很快,近两年的几个项目是:
- QueryGPT(Uber 2024年),是个端到端的系统,使用LLM(GPT-4)构建了多步骤的管道,并结合检索和代理模块。整体架构类似RAG方法,给定一个问题,首先对实例查询以及架构信息的向量库进行相似性搜索,获取上下文。这些示例和架构片段作为小样本提示提供给 LLM,指导其生成 SQL。由于 Uber 的数据生态系统非常复杂(有些表有 200+ 列),因此 QueryGPT 结合了专门的Agent来处理这些复杂的场景。意图Agent 将用户的请求分类成特定的业务域(例如“手机”或“广告”),从而缩小相关的表和示例查询的范围。然后, 表Agent 会建议查询应使用的特定表,从而允许用户反馈以更正表选择中的任何错误。在生成之前, 列修剪Agent 从这些表的结构中修剪不相关的列,以减少提示词长度(在使用具有有限上下文窗口的模型时至关重要)。最后,通过LLM生成一个 SQL查询(以及对应的解释),该查询将结果返回给用户。这种分层设计结合了检索、域过滤和迭代优化,使QueryGPT能够在128K Token的GPT-4上下文中处理Uber的大型架构,并可靠地生成复杂的多表查询。QueryGPT 体现了一种 混合架构 ,其中多个对模型的调用专注于子任务(如意图分类、架构选择等),从而最终生成准确的SQL。值得注意的是,它作为生产服务运行,到 2024 年中,它为数千名 Uber 员工在制定运营查询方面节省了大量时间。
- DIN-SQL (2023),利用了一些最先进的提示词策略,而不是新的模型架构。关键思想是利用 思维链分解 :DIN-SQL 不是提示 LLM 直接输出最终的 SQL,而是将生成分解为更小的子问题,并逐步将中间解决方案反馈到模型中,例如,可能首先提示 LLM 确定哪些表和列是相关的,然后制定部分子句(SELECT、WHERE),最后组合和验证完整的查询。DIN-SQL 还引入了 自我纠正循环 ,其中分析 LLM 的初始答案,如果检测到错误(例如,与 schema 或执行结果不匹配),则提示模型修改其查询。这种 分解的提示 + 反馈 方法在小样本情况下 产生了显著的准确率提升 (~+10%)。在 Spider 基准测试中创下了新纪录,测试集的执行准确率为 85.3%,超过了之前的所有微调模型。它还在较新的 BIRD 基准测试中达到了最先进的水平(55.9% 的执行准确率)。DIN-SQL 系统强调了提示工程如何释放 LLM 的推理能力:通过引导模型完成类似于人类解决查询的推理过程(逐步和反射),它无需额外培训即可缩小性能差距。
- SQLCoder**(Defog, 2023–2024)** 代表了一系列专门用于 NL2SQL 的微调 LLM,展示了将模型专门用于此任务的能力。SQLCoder 模型由 Defog 公司开发,基于开源LLM(Meta 的最新版本为 CodeLlama),并使用了大量文本到 SQL示例进行微调。他们发布了各种比例的模型(7B、15B 和高达 70B 参数的模型)。最大的 SQLCoder-70B 在许多基准测试中都取得了接近人类的性能,在新的的数据架构和问题上达到 93% 的准确率。在公司的评估套件上的表现甚至超过了 GPT-4 和 Claude。由于微调,它通常可以为领域内的查询生成具有非常高精度的正确 SQL。其中的较小的版本(SQLCoder-7B 和 15B)以一定的准确性换取了速度和可部署性,例如,7B 模型足够小,可以在消费类硬件 (≈8 GB GPU)上运行,支持本地和实时用例。通过开源这些模型,SQLCoder 使研究人员能够试验最先进的 NL2SQL,而无需依赖封闭的 API。例如,据报道,SQLCoder-70B 模型可以处理涉及日期、分组、联接和嵌套逻辑的复杂查询,在许多情况下的准确性高于 GPT-4。
NL2SQL架构发展趋势
当前架构发展来看,几乎所有性能最好的方法都在使用大语言模型。这是因为LLM在理解自然语言和生成结构化文本方面具有卓越的能力。部分架构是端到端的(直接使用LLM转换SQL),另一部分架构是混合多个组件或阶段的混合pipeline。现代 NL2SQL 架构将强大的序列模型与特定于问题的增强功能相结合:大型 LLM 提供了强大的生成 SQL 的先验能力,而检索、结构化架构表示和基于搜索的优化解决了特定于数据库的解析的细微差别。
Uber的QueryGPT
第一版:
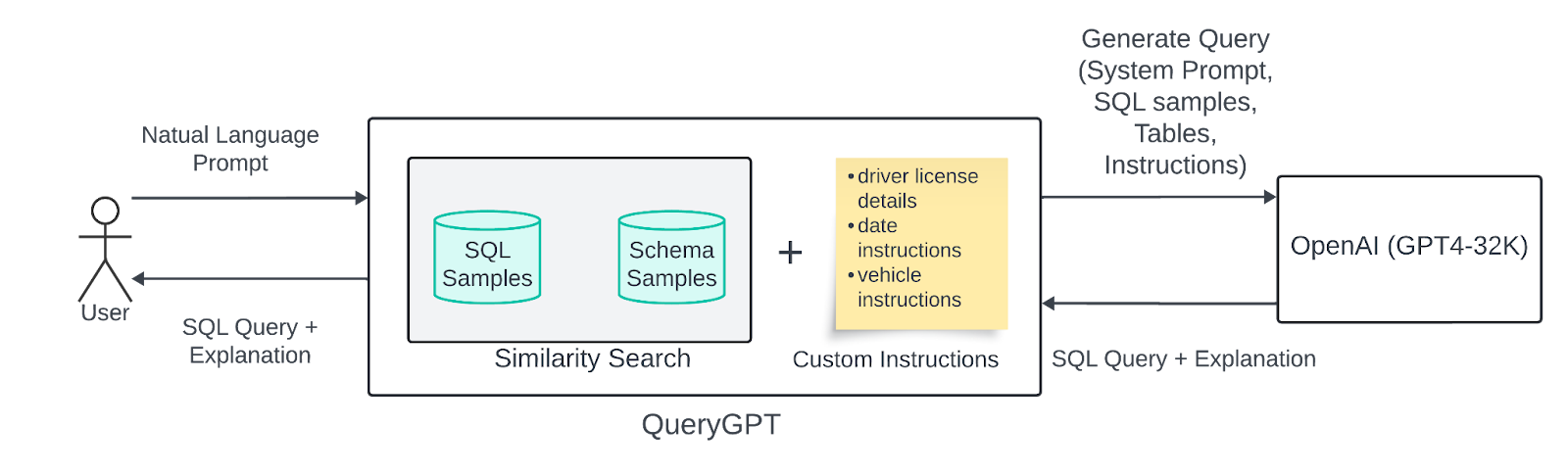 ![[Pasted_image_20250629232734.png]]
![[Pasted_image_20250629232734.png]]
当前版本:
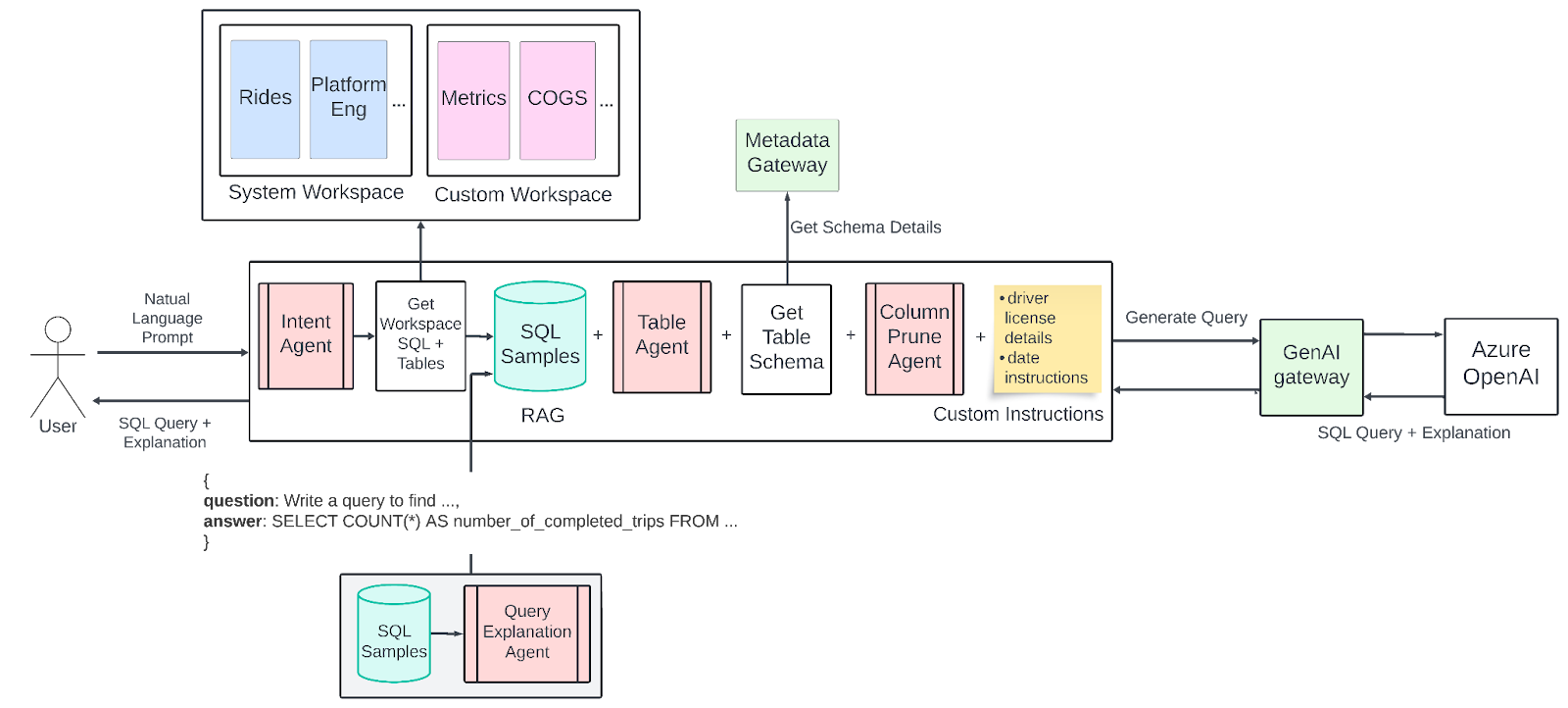 ![[Pasted_image_20250629232701.png]]
![[Pasted_image_20250629232701.png]]